
이와 함께 데이터를 제공하는 국민이 신약 개발로 발생한 수익을 배당받는 ‘국민신약배당’ 정책 도입도 제안됐다.
11일 김화종 K-멜로디(연합학습 기반 신약개발 가속화 프로젝트) 사업단장은 온라인 간담회를 통해 이같은 내용을 처음 소개했다.
이번 제안된 내용은 국내 구축된 바이오데이터를 신약개발에 활용할 수 있게 정부가 나서 AI모델로 개발하는 사업을 추진해야 한다는 것이다. 신약 개발 주체는 수익 일부를 공유화하겠다는 계약을 맺고 해당 AI모델을 사용하는 방식이다.
김 단장은 “우리나라는 바이오신약개발 후발 주자다. 대신 단일 의료보험 체계 등으로 데이터 정리가 잘 돼 있다. 원천 데이터 소유자(국민)에 대한 보상을 통해 국민 바이오데이터를 블록버스터 신약 개발에 활용할 수 있다”고 말했다.
발표에 따르면 국내 제약산업 규모는 글로벌 대비 1.8% 수준에 그친다. 선진국과 경쟁을 위해선 블록버스터 신약 개발이 필요한데, 이를 위해선 신약 개발에 더 많은 데이터가 요구된다.
다만 현재 수준에선 생체 정보 민감도나 사용처에 대한 불명확성으로 데이터 수집에 어려움이 있다. 또 유전체 정보, 건강보험청구 정보 등 데이터는 정보보호법상 기관 외에서 활용이 제한돼 있다.
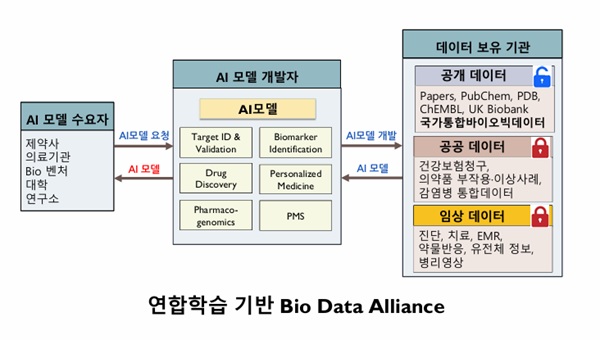
이를 연합학습이라고 하는데, 정부 주도 하에 데이터 보유 기관 내에서 AI모델을 만들고 이를 제약사, 의료기관, 연구소 등 신약 개발 주체가 활용할 수 있게 한다는 것이다. 데이터 자체가 기관 외로 유출되지 않는다는 점에서 개인정보보호에 대한 우려를 해소할 수 있다.
글로벌에서는 이미 다수 기관이 협업해 신약 개발을 위한 데이터 구축에 나서고 있다. 대표적으로 K-멜로디 모티브가 된 EU멜로디에서는 노바티스, 바이엘, 아스트라제네카, 얀센 등 10여 곳 제약사가 협업해 각자 보유하고 있는 데이터를 화합물활성, 약물-타깃 데이터 생성 등에 활용하고 있다. 기업별 모델 대비 협업 모델 예측 정확도가 5~10% 향상된 것으로 알려졌다.
김 단장은 “우리나라 임상시험체계는 세계 탑5 수준으로 정보체계가 잘 발달돼 있다. 임상·공공 바이오데이터를 AI 신약개발에 효과적으로 활용하는 기술과 제도를 도입해 수익을 내고 국민과 공유하는 선순환 구조를 만들고자 정책을 제안하게 됐다”고 말했다.
[소비자가만드는신문=정현철 기자]
